Router的作用被低估了?vLLM这个神器,让单次调用背后藏了一支模型协作小队
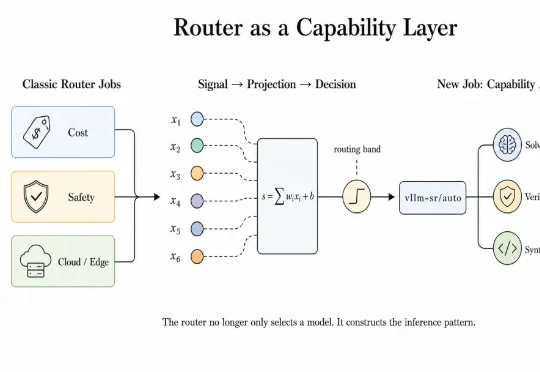
Router的作用被低估了?vLLM这个神器,让单次调用背后藏了一支模型协作小队vLLM 社区推出的 Semantic Router 除了专注上面三个方向,正在更进一步:我们认为:router 不只是选择模型,还可以提升模型能力。用户不用改权重,也不用让每个 Agent 团队都自己搭一套 Graph,而是在一次普通 Model API 调用的内部,组织出一支有边界、有预算、有验证、有回退的 “小队”。
来自主题: AI技术研报
8406 点击 2026-07-05 09:43